GPT-4V全称是GPT-4 with Vision,是一个多模态的能力,它可以理解图片,为用户解析图片并回答图片相关的问题。GPT-4V可以准确理解图像的内容,识别图像中物体、计算物体的数量、提供图片相关的洞察和信息、提取文本...
”vison“ 的搜索结果
注意文本工具的图像输入必须是找原点工具的输出(不能是原图像),因为文本显示的位置是根据原点的相对位置显示的。因为零件瑕疵检测时,有部分零件与正常零件不同,要用掩膜工具去掉感兴趣的部分。...
VisionMaster(后简称VM)作为一款功能强大的工业图形图像处理软件,可对工业中遇到的各种图像进行处理,同时还有功能强大的算子以及很全面的例程,作为图像处理的主程序是非常不错的。当前VM提供了VM算法平台、VM ...
Swin Transformer与Vision Transformer的不同设计图片分割cls_token位置编码attention层 图片分割 Swin使用一个卷积层进行分割,卷积层的滑动补偿等于核的尺寸,因此图片每个像素不会重复框选,卷积核数等于...
用labview制作的图片浏览器,可以看到ROI,适用于Vision函数库定义的ROI图片和一般PNG,JPG格式图片。仿制windows图片浏览器的功能。必须有labview运行库才能运行!

坑:一定要 右键在这个bat上面以管理员身份运行,不要直接运行否则会失败;还有编码,ANSI编码!

找到并复制其中的下载链接 https://raw.githubusercontent.com/opencv/opencv_3rdparty/bf1730f4c4ba1996bed1fe268b52e4e942151cd6/ffmpeg/opencv_ffmpeg.dll。我的配置: Vitis Vision 2022 + opencv-4.4.0 + ...
Vision Transformer的计算复杂度取决于多个因素,如模型结构、输入图像的大小、Transformer层数等。具体来说,假设我们有一个输入图像大小为$H \times W \times C$,Transformer模型有$L$层,每层有$d_{model}$维词...




视觉转换器是深度学习领域中流行的转换器之一。在视觉转换器出现之前,我们不得不在计算机视觉中使用卷积神经网络来完成复杂的任务。随着视觉转换器的引入,我们获得了一个更强大的计算机视觉任务模型。...
【论文讲解】CMT: Convolutional Neural Networks Meet Vision Transformers

机器视觉常用接口
Transformer 是 Google 的团队在 2017 年提出的一种 NLP 经典模型,现在比较火热的 Bert 也是基于 Transformer。Transformer 模型使用了 Self-Attention 机制,不采用 RNN 的** 顺序结构**,使得模型可以并行化训练...
这篇论文是CVPR2023的一篇论文,主要工作是对于Vision Transformer的自注意力机制进行了魔改。我感觉这篇文章或许对我的工作有帮助,因此,今天精读一下。(侵权删)(非常欢迎来argue,指正我的错误)

VISIO输出黑白色电路图
标签: visio
方法 直接把AD的图复制到VISIO中,是彩色的,然后选另存为TIF格式的,然后在接下来的选择中,就可以选256灰度的了,颜色就是黑白灰。然后可以根据自己喜欢的分辨率进行设置。 Visio高分辨率图片输出流程 ...

微信小程序3D,使用Three.js在微信小程序中展示gltf模型,使用VisionKit展示AR能力
注意!在安装NVIDIA驱动以前需要禁止系统自带显卡驱动nouveau:可以先通过指令查看nouveau驱动的启用情况,如果有输出表示nouveau驱动正在工作,如果没有内容输出则表示已经禁用了nouveau。如果没有禁用ubuntu自带的...
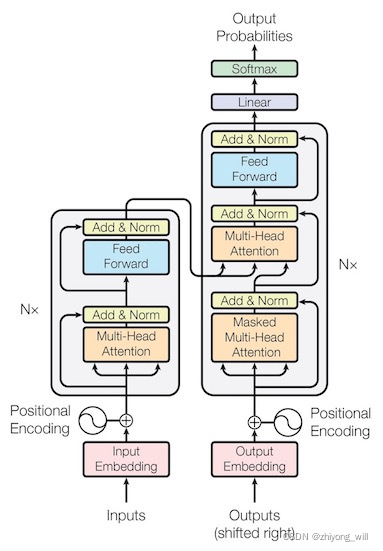
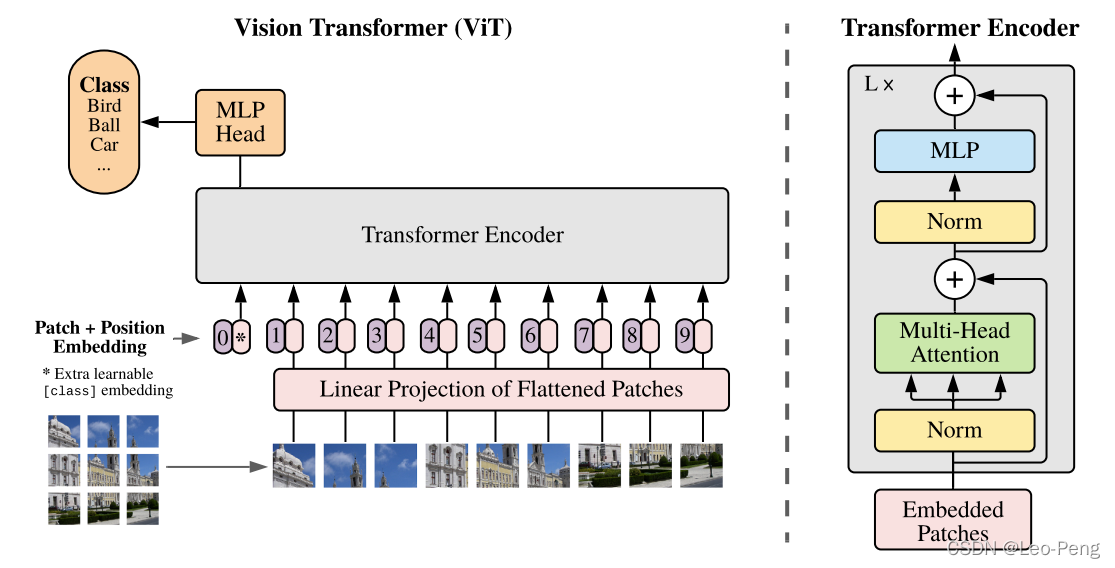
虽然Transformer架构已经成为自然语言处理任务的事实标准,但它在计算机视觉方面的应用仍然有限。在视觉中,注意力要么与卷积网络一起应用,要么用来替换卷积网络的某些组件,同时保持它们的总体结构。...

推荐文章
- 阿里云企业邮箱的stmp服务器地址_阿里云stmp地址-程序员宅基地
- c++ 判断数学表达式有效性_高考数学大题如何"保分"?学霸教你六大绝招!...-程序员宅基地
- 处理office365登录出现服务器问题_o365登陆显示网络异常-程序员宅基地
- Nginx RTMP源码分析--ngx_rtmp_live_module源码分析之添加stream_ngx_rtmp_live_module 原理-程序员宅基地
- 基于Ansible+Python开发运维巡检工具_automation_inspector.tar.gz-程序员宅基地
- Linux Shell - if 语句和判断表达式_shell if elif-程序员宅基地
- python升序和降序排序_Python排序列表数组方法–通过示例解释升序和降序-程序员宅基地
- jenkins 构建前执行shell_Jenkins – 在构建之前执行脚本,然后让用户确认构建-程序员宅基地
- 如何完全卸载MySQL_mysql怎么卸载干净-程序员宅基地
- AndroidO Treble架构下HIDL服务查询过程_found dead hwbinder service-程序员宅基地